Socrates-1.1 just scored 72 on Terminal-Bench Hard

Socrates-1.1 just scored 72% on Terminal-Bench Hard.
That puts a TrustedRouter combo model ahead of the frontier baselines people were treating as the ceiling. The AI IQ Terminal-Bench Hard chart currently lists Fable 5 at 63, GPT-5.5 at 61, and Opus 4.8 at 58. The new Socrates-1.1 run is 72. It also beat the GPT-5.6 comparison run we were using locally, while running faster and cheaper than the closed frontier comparison set.
This is the point of combo models. No model has a monopoly on knowledge. A bigger model does not automatically contain every strength of a smaller one. The models learn different things, miss different things, and break in different places. When the task is hard enough, those differences are useful.
Terminal-Bench Hard is a good place to see it because the benchmark is annoying in the right way. It asks models to fix real terminal tasks. Cancel async work. Patch a vuln. Move across languages. Read Rust and C. Debug a webserver. Recover a password. These are not clean trivia questions with one memorized answer. They are little software jobs, and little software jobs punish models that are good in the average case but bad at the weird edge.
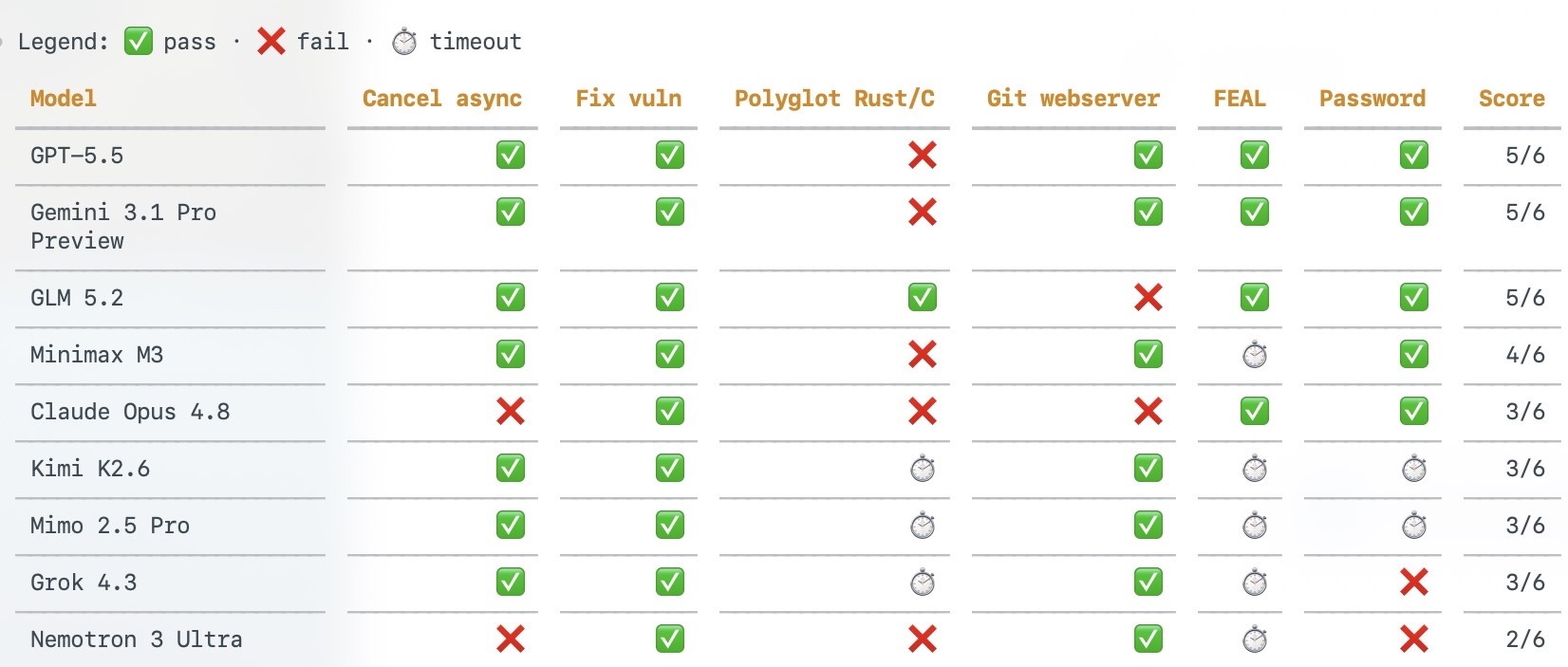
Look at the sample. GPT-5.5 and Gemini 3.1 Pro get five of six in this slice, but both miss Rust/C. GLM 5.2 gets Rust/C and misses the webserver. MiniMax M3 gets four and times out on FEAL. Opus gets three. Kimi gets three with timeouts. Nobody owns the whole table.
The combination is plain engineering. Ask several strong models. Let them fail in different places. Use a strong synthesizer to keep the useful parts and throw away the bad parts. This is why Synth exists, and why the earlier DRACO result mattered. The same idea is showing up again on Terminal-Bench Hard.
The important part is the API shape. You do not need to wire a research harness into your app to use this. You call trustedrouter/socrates-1.1 through the normal OpenAI-compatible endpoint. Behind that model id, the attested gateway can run the worker, the nested advisor chain, and the final synthesis, then return one answer. It is the same model-container idea from the combo models post, now with a score that is hard to ignore.
There is an obvious objection. Ensembles are old. Yes. So are compilers and databases. The useful thing is making the abstraction boring enough that people can depend on it. A model id should be able to package a real graph of model calls, publish its score, publish its sub-models, and run inside infrastructure that developers can verify. That is the line from attestation to open models to combo models.
TrustedRouter is built for that. The model pages show the routes. The leaderboard shows health and latency. The trust page lets an agent verify the gateway binary before sending prompts. The score is the exciting part, but the product only matters if people can use the winning model without handing their terminal session to a black box.
Socrates-1.1 is now the leading model in our Terminal-Bench Hard run. The strongest answer is often spread across several models, and the router can finally make that usable as one model.